目次
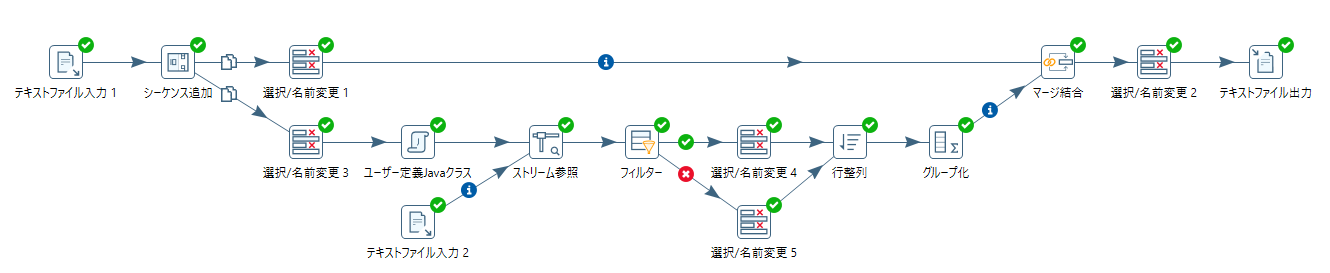
102.1文字毎の置換例
2024-01-14
文字列を1文字ずつ分解して対応表で変換する例。
希望の結果
テキストファイル入力 1 の文字列を、テキストファイル入力 2 の対応表に従って置換し(対応表に無ければそのまま)、置換結果をテキストファイル出力へ出力する。
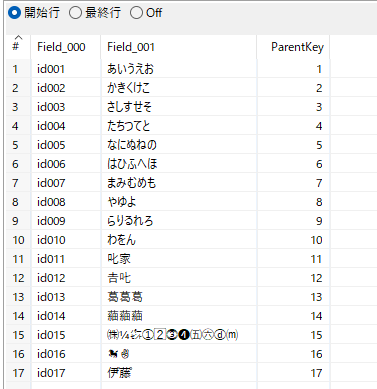
| テキストファイル入力 1 | テキストファイル入力 2 | テキストファイル出力 |
|---|---|---|
id001,あいうえお id002,かきくけこ id003,さしすせそ id004,たちつてと id005,なにぬねの id006,はひふへほ id007,まみむめも id008,やゆよ id009,らりるれろ id010,わをん id011,叱家 id012,𠮷𠮟 id013,葛葛󠄉葛󠄀 id014,𦹀𦹀󠄃𦹀󠄂 id015,㈱¼㌫①2⃣⓷❹㈤㊅ⓓ⒨ id016,🐎✌ id017,伊゙藤゚ | あ,ア い,イ う,ウ え,エ お,オ さ,■ し,■ す,ス せ,■ そ,■ た,■ ち,■ つ,ツ て,■ と,■ な,■ に,■ ぬ,ヌ ね,■ の,■ わ,■ を,ヲ ん,■ 𠮷,吉 𠮟,叱 葛󠄉,葛 葛󠄀,葛 𦹀󠄃,𦹀 𦹀󠄂,𦹀 | id001,あいうえお,アイウエオ id002,かきくけこ,かきくけこ id003,さしすせそ,■■ス■■ id004,たちつてと,■■ツ■■ id005,なにぬねの,■■ヌ■■ id006,はひふへほ,はひふへほ id007,まみむめも,まみむめも id008,やゆよ,やゆよ id009,らりるれろ,らりるれろ id010,わをん,■ヲ■ id011,叱家,叱家 id012,𠮷𠮟,吉叱 id013,葛葛󠄉葛󠄀,葛葛葛 id014,𦹀𦹀󠄃𦹀󠄂,𦹀𦹀𦹀 id015,㈱¼㌫①2⃣⓷❹㈤㊅ⓓ⒨,㈱¼㌫①2⃣⓷❹㈤㊅ⓓ⒨ id016,🐎✌,🐎✌ id017,伊゙藤゚,伊゙藤゚ |
定義
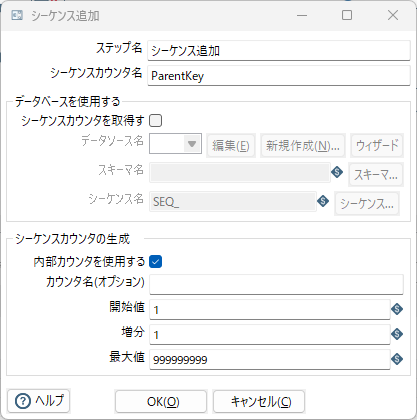
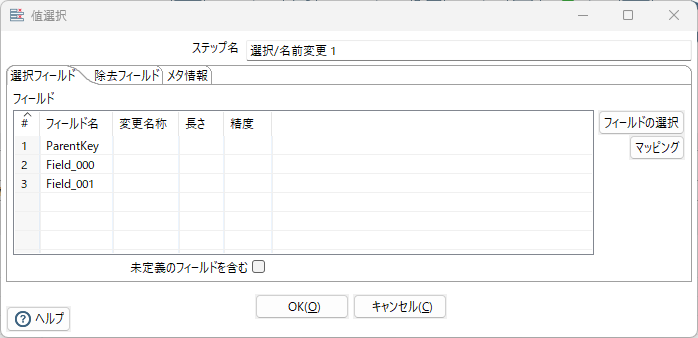
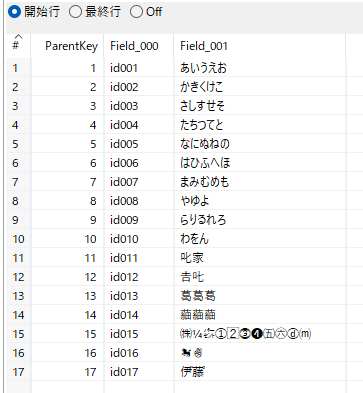
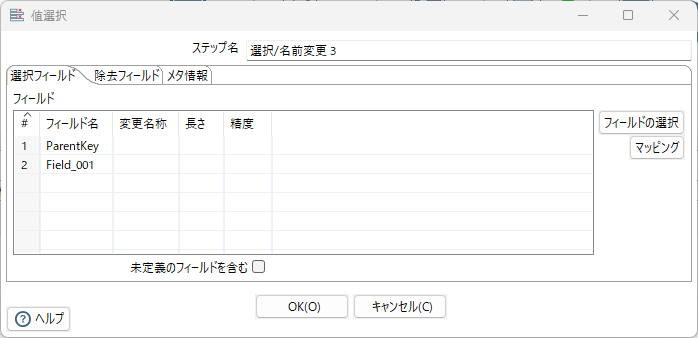
シーケンス追加、選択/名前変更 1、選択/名前変更 3
テキストファイル入力 1を変換部と非変換部に分離するので、後で元に戻すための主キーになるシーケンスナンバーを付与する。次に入力行を変換、非変換の2種類に分ける。
- 非変換→選択/名前変更 1へ主キーと非変換部、変換前文字列
- 変換→選択/名前変更 3へ主キーと変換対象文字列
分岐に際しては「コピー」を選択する事。「分配」だと正しい処理ができない。※同じ内容を受け取ってから必要な項目をそれぞれで設定する為。
| 定義 | 出力 |
|---|---|
 |  |
 |  |
 |  |
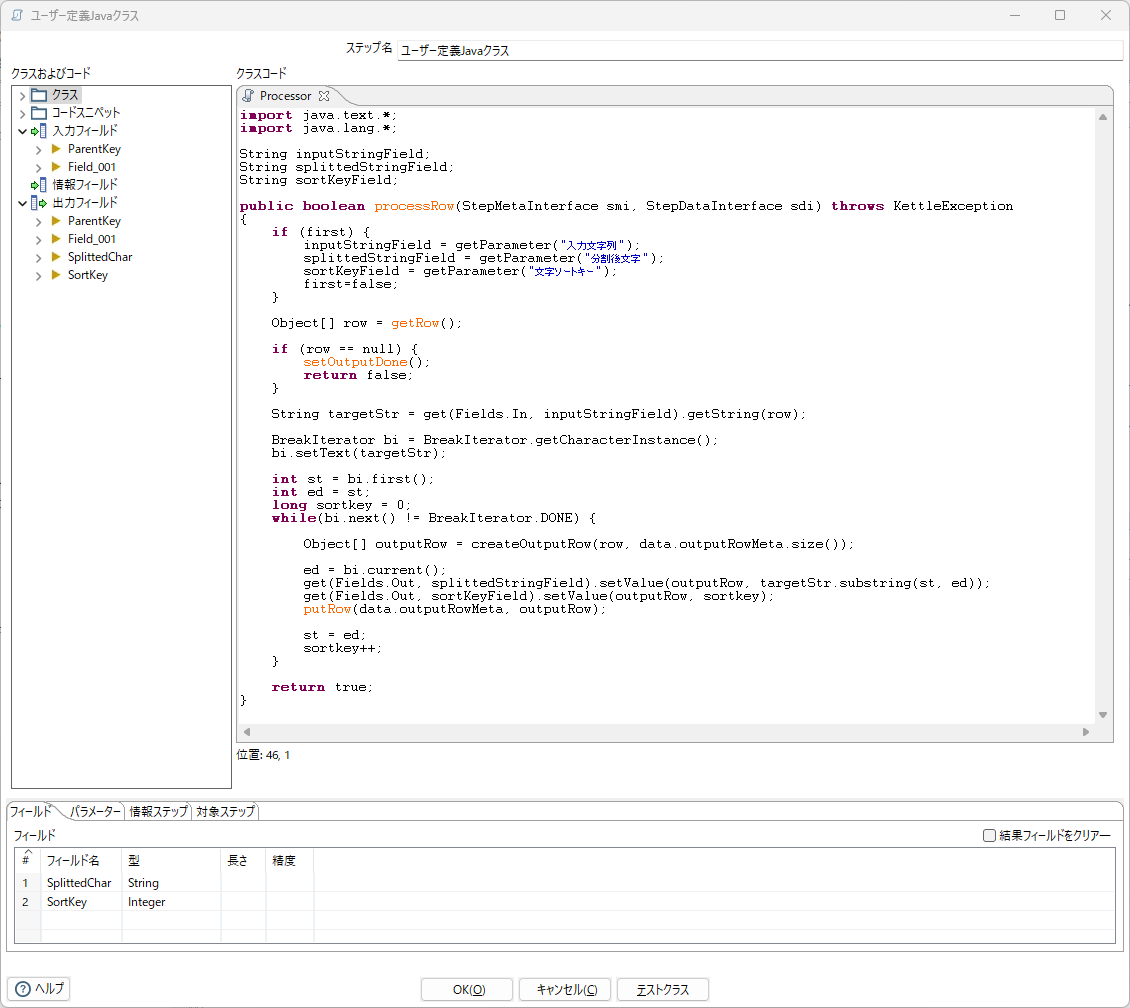
ユーザー定義Javaクラス
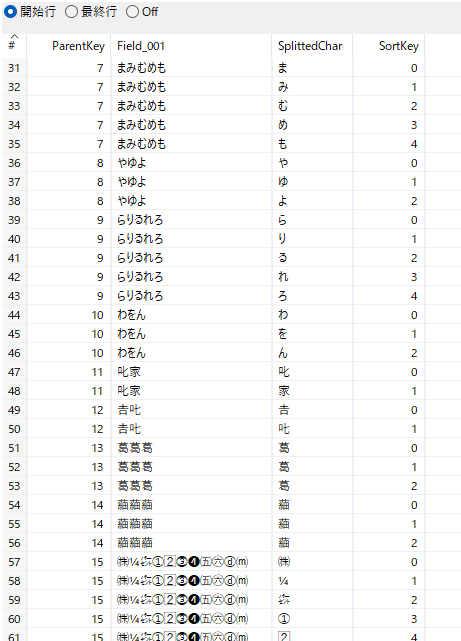
入力した文字列の文字個数がn個であれば、n行の出力を行う。文字分解に java.text.BreakIterator を利用した。利用するJavaの版によって固有の制限や問題があると思うが検証はしない。
新たに作るレコードに主キーの項目を作る必要は無かった。先に読んだレコードの内容が出力されていた。
分解した1文字を項目SplittedCharに格納し、文字列中での順番を示す項目SortKeyを追加している。
| 定義 | 出力 |
|---|---|
  |  |
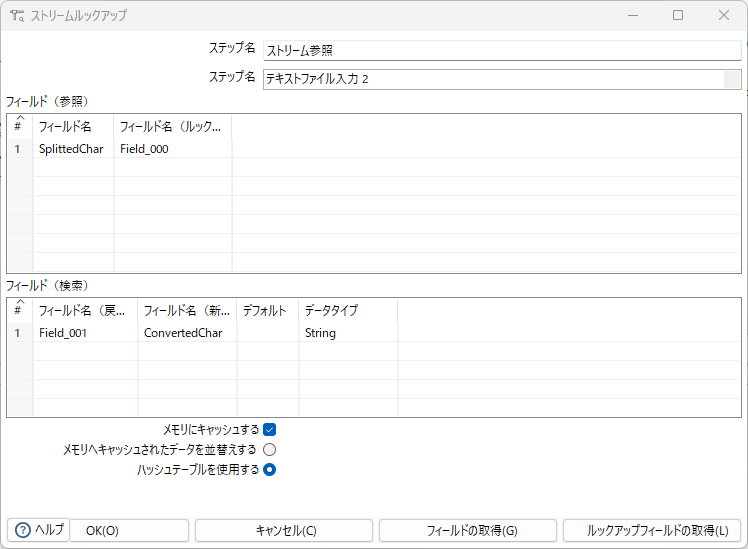
ストリーム参照
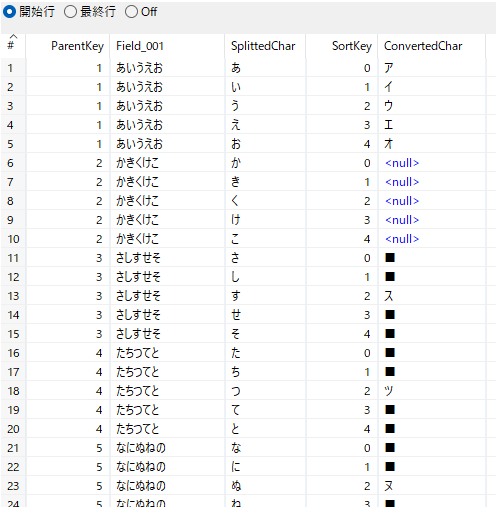
テキストファイル入力 2を文字変換表として利用する。変換表に定義の無い文字があると結果がnullになるためこれだけで完結はできないので注意。
項目ConvertedCharにnullが入る文字は、文字変換表に定義が行われていない文字を意味する。
| 定義 | 出力 |
|---|---|
 |  |
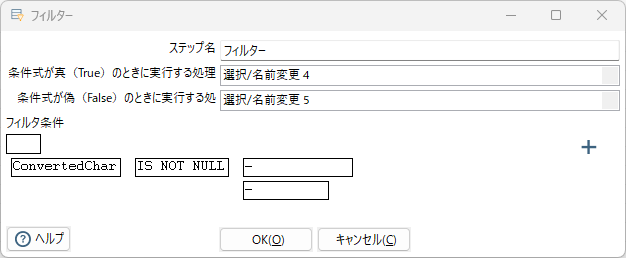
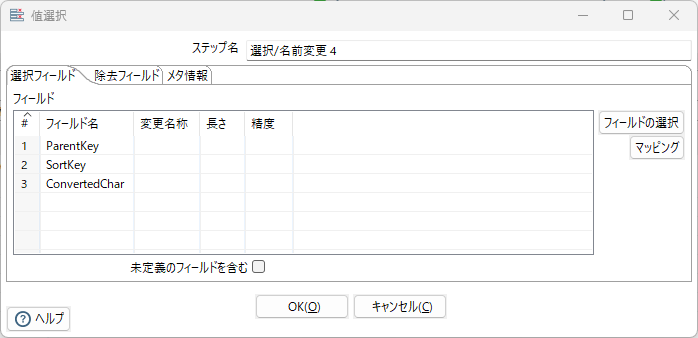
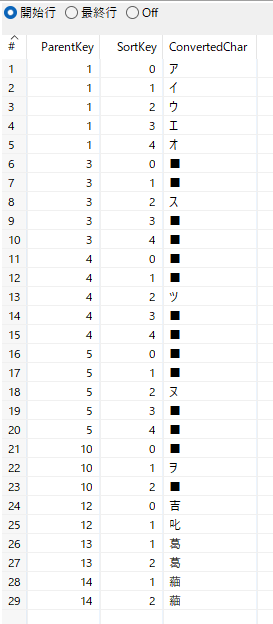
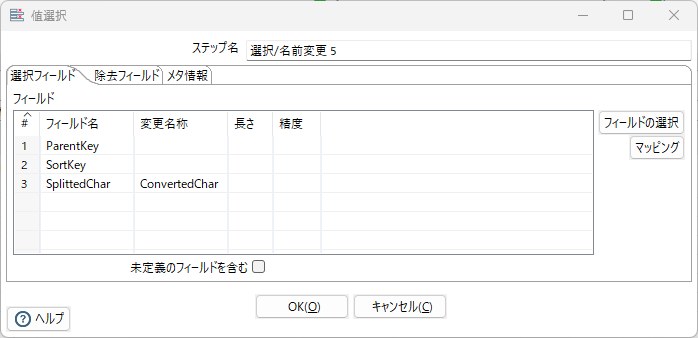
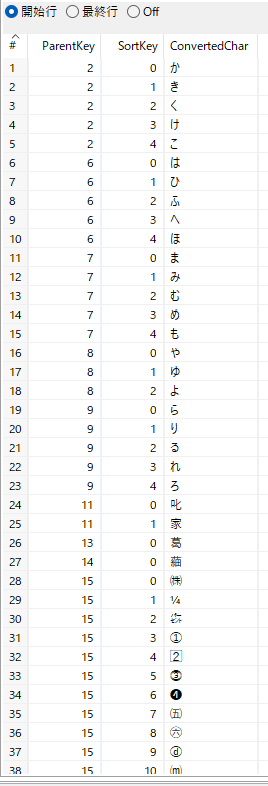
フィルター、選択/名前変更 4、選択/名前変更 5
項目ConvertedCharがnullでなければ選択/名前変更 4へ遷移、nullなら選択/名前変更 5へ遷移する。
名前変更 5で項目SplittedCharをConvertedCharとして使用する。
| 定義 | 出力 |
|---|---|
 |
|
 |  |
 |  |
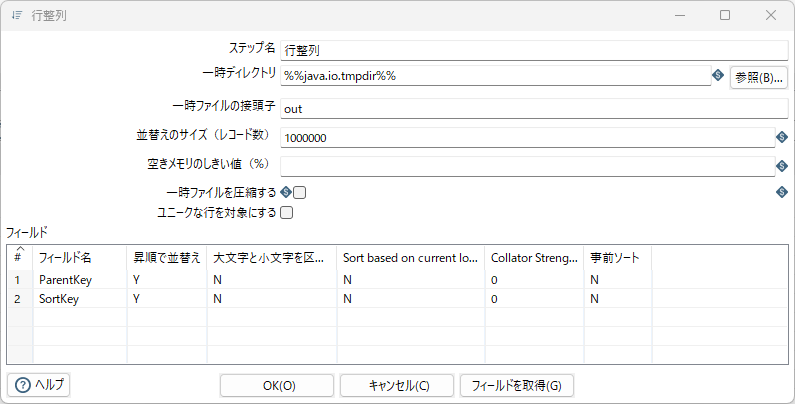
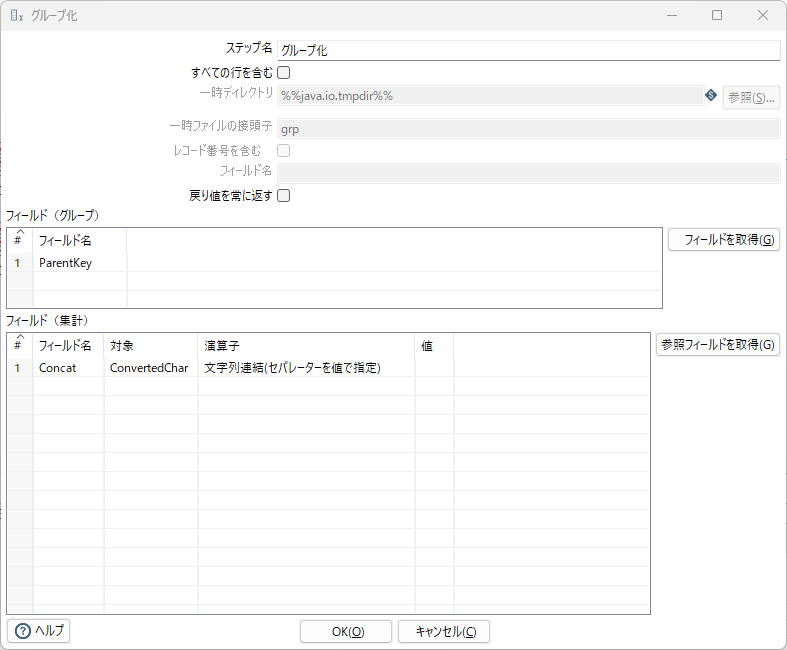
行整列、グループ化
行整列で、項目ParentKey,SortKeyをキーにしてソートする。これは後続のグループ化で必須の条件。
演算子に「文字列連結(セパレーターを値で指定)」を指定すると、対象のレコードの項目ConvertedCharを順に結合していく。これが変換後文字列となる。
| 定義 | 出力 |
|---|---|
 |  |
 |  |
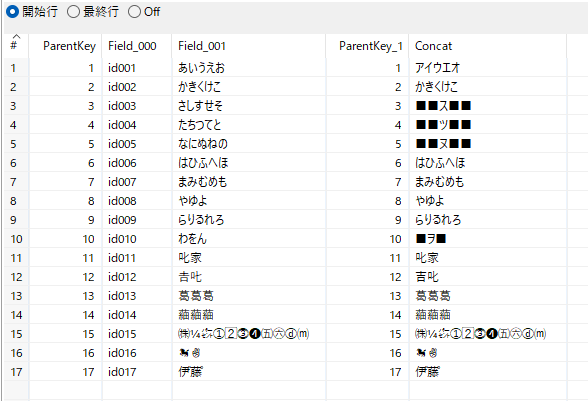
マージ結合
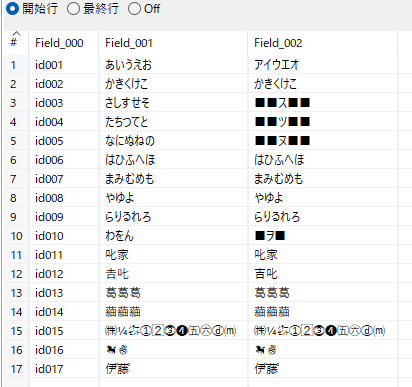
選択/名前変更 1の出力とグループ化の出力を項目ParentKeyで1行に集約する。1対1で結合するのでINNERを選択している。
選択/名前変更 1の項目Field_001が更新前文字列、グループ化の項目Concatが変更後文字列、となる。
| 定義 | 出力 |
|---|---|
 |  |
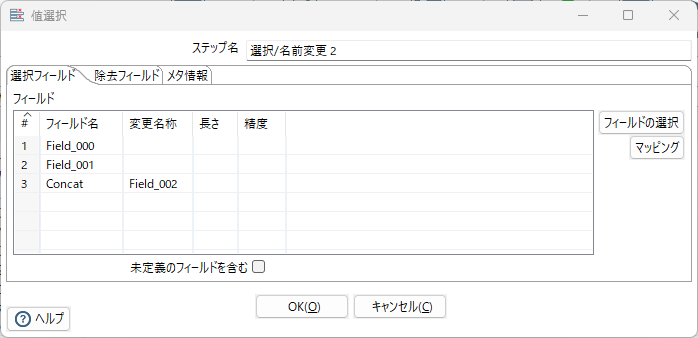
選択/名前変更 2
あとはマージ結果の出力を成型するだけ。
| 定義 | 出力 |
|---|---|
 |  |